Hyperliquid Precompiles, An Inconvenient Truth
Engineering
Hyperliquid Precompiles allow for read and writes between HyperEVM and HyperCore, enabling EVM applications to access the liquidity and functionality of Hyperliquid perps and more. They are broken down into CoreWriter Actions, which allow for transactions on HyperEVM that mutate state on HyperCore. And Precompiles, which allow for reading HyperCore state on HyperEVM. This unlocks new categories of applications that can be built using this new composable infrastructure. For example, a fully permissionless liquid staked token on HyperEVM, that stakes and unstakes on HyperCore using CoreWriter actions. Or a Tokenised Vault on HyperEVM, that is backed by perpetual futures positions on HyperCore.
Show me the code
There is nothing better than seeing some example code to understand how things work in practice. Below is a simple example of a smart contract that bridges USDC from HyperEVM to HyperCore perps balance. And exposes a view that returns the total value of the smart contract, EVM balance plus perp balance.
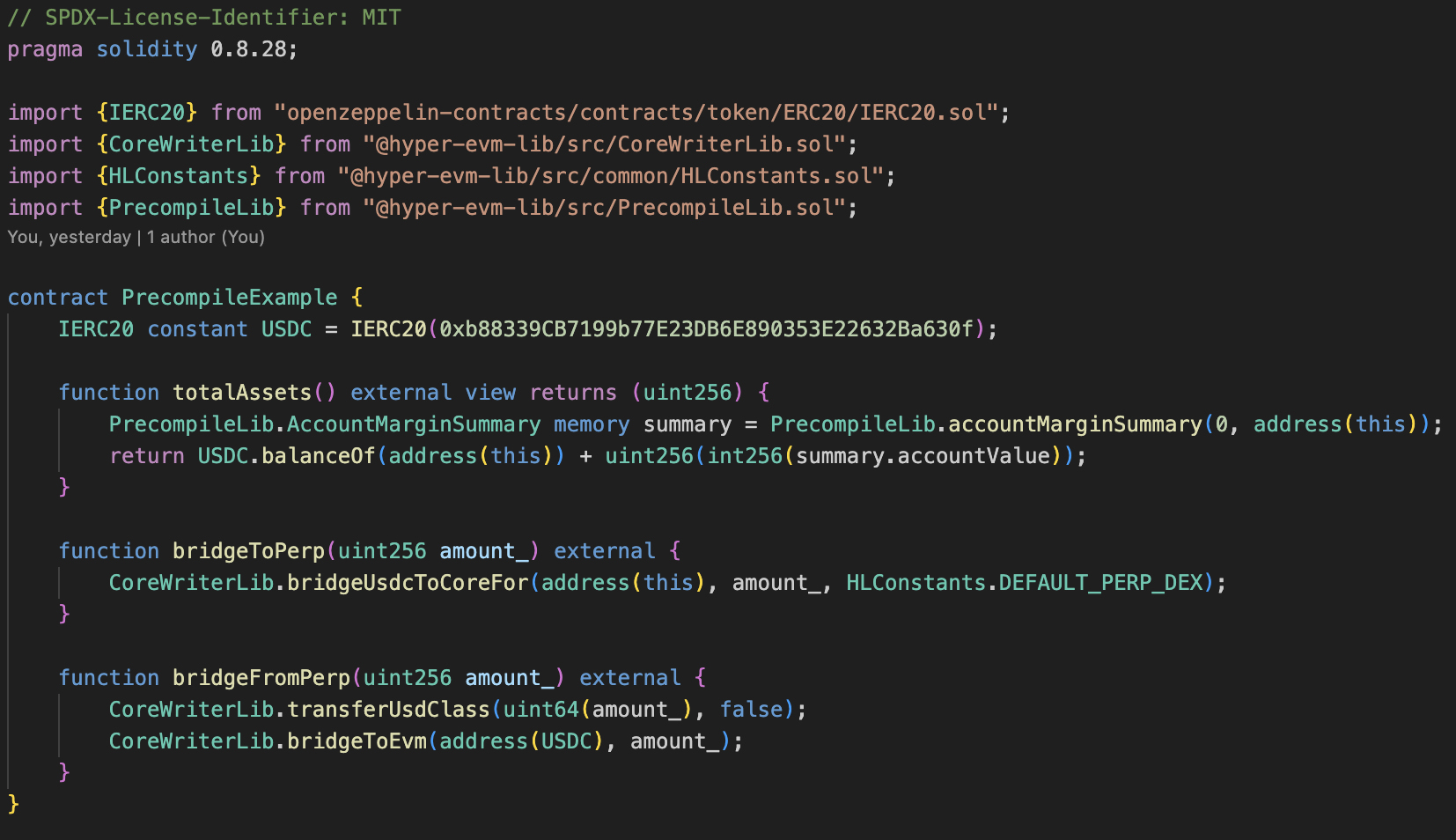
The totalAssets view is returning the USDC balance in the contract, and using the Account Margin Summary precompile to get the perp balance. The bridgeToPerp function is using a convenient CoreWriter Action that bridges from EVM to Perp balance in a single Action. And the bridgeFromPerp function is doing this in two steps, first transferring to spot, and then bridging from spot to EVM, as there is no shortcut way to do this in one transaction for the return. The code looks simple enough, and at a glance you can see how these Precompiles would be incredibly useful for building a host of applications that could not exist without them.
However, what lies under the murky depths of this deceptively simple Solidity code is a shiver of exploitable edge cases waiting to strike. We will be going into all of these in this article, and surfacing each of them. For many of which it will be the first time they have been publicly documented.
Atomic vs Async
One ongoing challenge is that all HyperEVM actions are atomic, while all CoreWriter actions are async. As EVM developers, we become quite accustomed to our atomic flows, where steps are guaranteed to happen within a single block, and if one thing reverts, the whole transaction does. With CoreWriter Actions however, the EVM side is more of a request for the action to be processed, and any validations are done after the EVM transaction has gone through. This means that a CoreWriter Action can succeed on the EVM side, but then later fail on the HyperCore side.
For example, looking at our bridgeFromPerp function. We first move our funds from perp to spot, and then from spot to EVM. However it would be theoretically possible for the first step to succeed, but for the second step to fail. Which would leave our funds stuck in the spot, with no way to recover them or to account for their balance in our existing contract.
There unfortunately is no golden spear solution for this problem. Other than ensuring you are doing as many validations as you can before submitting the CoreWriter Actions to try match the HyperCore validations. And to never assume that a transaction will go through when building. Often easier said than done.
Order of Events
With most use cases of precompile reads, the value returned by your contract usually has some security implications for its accuracy. For example, our totalAssets view may be used to determine the value of the smart contract, used to allocate the exchange rate the receipt tokens should be minted at, or the value that a user can borrow collateral against. If this totalAssets is incorrect for even the briefest moment, this could lead to exploits in the wider protocol.
This Atomic vs Async behaviour has one inconvenient implication. All EVM portions of the flow happen as soon as they are called within the block. However all CoreWriter Actions are processed by the next EVM block. Let us look at the flow for our bridgeToPerp function:
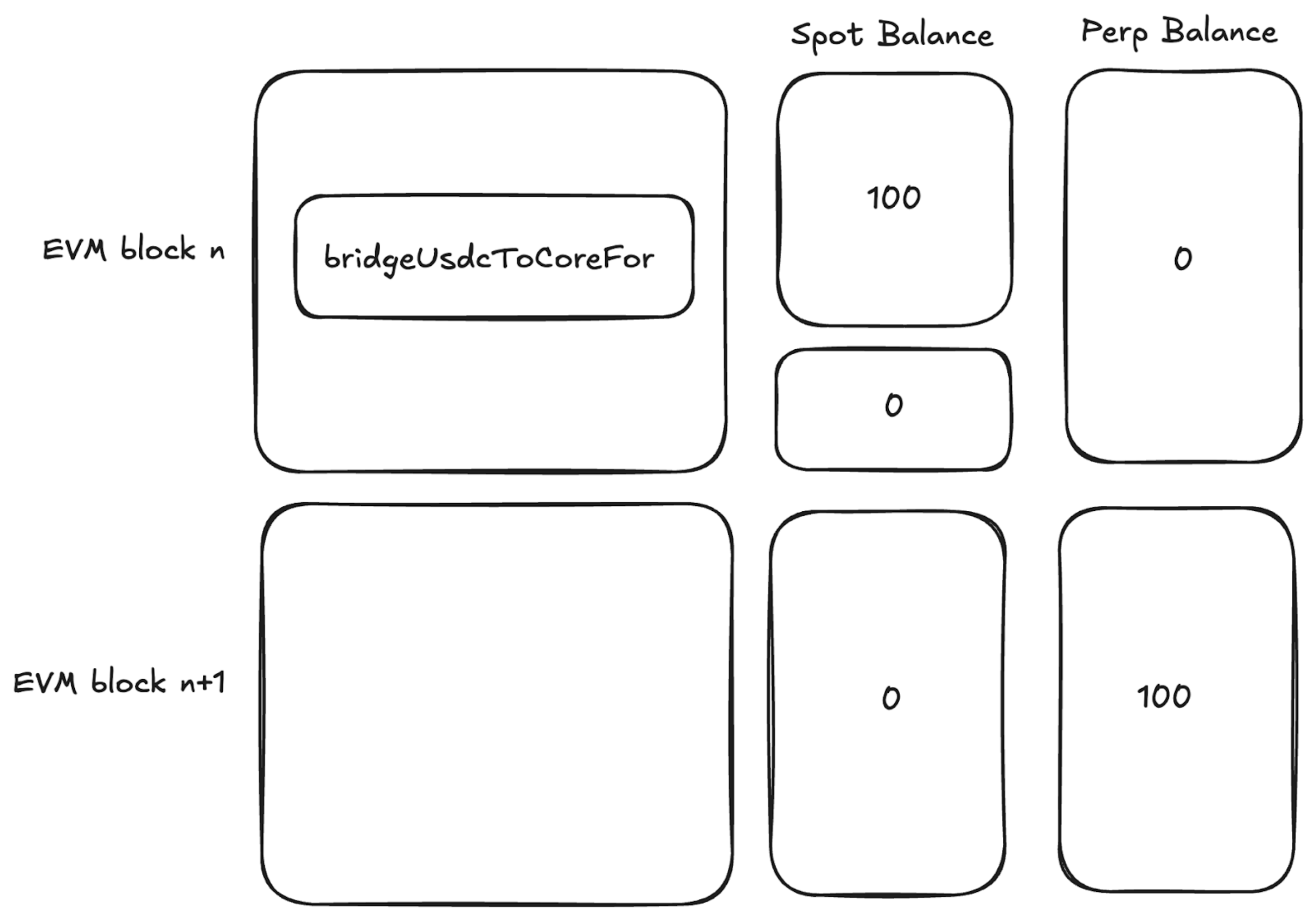
On the left are the EVM blocks, and we can see in block n we are calling the CoreWriterAction bridgeUsdcToCoreFor half way through the EVM block. On the right are our balances throughout this flow. What happens, is that as soon as the CoreWriter Action is called, our USDC is taken, to prevent double spending. However, our perp balance is not updated until the next EVM block once the action has been processed. This means that for a brief period, within block n but after our bridge call, the funds have been lost at sea. Which could be capitalised on by a willing pirate who smuggles a transaction into block n after the bridge, to capitalise on the now incorrect totalAssets view.
To remediate this, a new storage value is needed in the contract that tracks the amount that is currently being bridged for each block. Then in the totalAssets view, this bridging amount would need to be added to the total to fill in the temporary gap.
USDC Quirks
The USDC bridge linking HyperEVM and HyperCore was a big unlock. Allowing for bridging native USDC between chains using Precompiles. There are however some hidden edge cases that need to be considered when integrating.
The first is that Circle has a function in their bridge disableDexForwarding (see here) that allows them to disable the functionality to bridge directly to your perps balance. What this means, is if you integrate with them to bridge directly from EVM to perp balance. They could at any time change this behaviour so that instead your funds are bridged to spot. Failing to account for this would mean funds are stuck in spot, with the full bridge flow failing. To account for this developers need to have a back up bridging flow that they switch to when the perps bridge is disabled.
Another inconvenience is that the HyperEVM and HyperCore USDC bridge is not backed 1:1 with USDC. There is more USDC on HyperCore than there is in the USDC bridge. Which means it is possible that the USDC bridge could run out of USDC, causing bridges from perps to fail. There is no easy way to account for this, other than being aware with all integrations, that bridges can fail, with no remediation other than waiting until funds are replenished. This makes many classifications of protocols quite risky to build, including anything that depends on borrowing, as collateral could not be able to be liquidated when needed.
Fees and Activation
If you start testing in production, you will quickly find that nothing is working. Bridging transactions are not going through, none of your CoreWriter Actions are triggering. And from the error messages, it is not clear why. The likely reason is that you have not paid the various fees required for these actions to go through.
The first one is that for any CoreWriter action to work, the Smart Contract must first be Activated. To do this, you need to send some USDC to it on HyperCore. This triggers the Activation process. 1 USDC should be enough, we are always paranoid and send 2.
The second common issue here is that bridging CoreWriter Actions are not free, and require balances to pay for fees. Bridging from Core to EVM requires HYPE or USDC on HyperCore spot. If you have both balances, it will take from the HYPE balance first. And bridging from EVM to Core requires HYPE on HyperEVM. For any production protocol, it is necessary to then manage these balances to ensure they always have enough for the bridge to go through, and if your architecture requires having multiple smart contracts, then you can quickly get into a web of balance management and topups.
Reading Views
Surely we can just read a smart contract view right? Surely there is no delicate web of requirements and edge cases for a simple read?
Inconveniently, it is not possible through any current RPC provider to query any smart contract view that includes a Precompile at a historic block. Querying at latest works most of the time. But querying anything in the past is not possible. This makes a whole host of product features impractical or impossible to implement. Even a simple feature like showing a chart of TVL is no simple feat. The workaround used for this is to create a database where precompile views are queried every block, once per second, and this data is written into a database. Which can then be queried for things like showing a chart of TVL. But this does not scale well when you start considering saving data that is not global, for example users specific views that take parameter inputs.
Most traditional blockchain indexing solutions do not work as almost all are using a backfill architecture. Where they historically query views to populate and build the database. Which will revert for any historic query.
Once a custom live indexing solution is in place, the data can show anomalies.
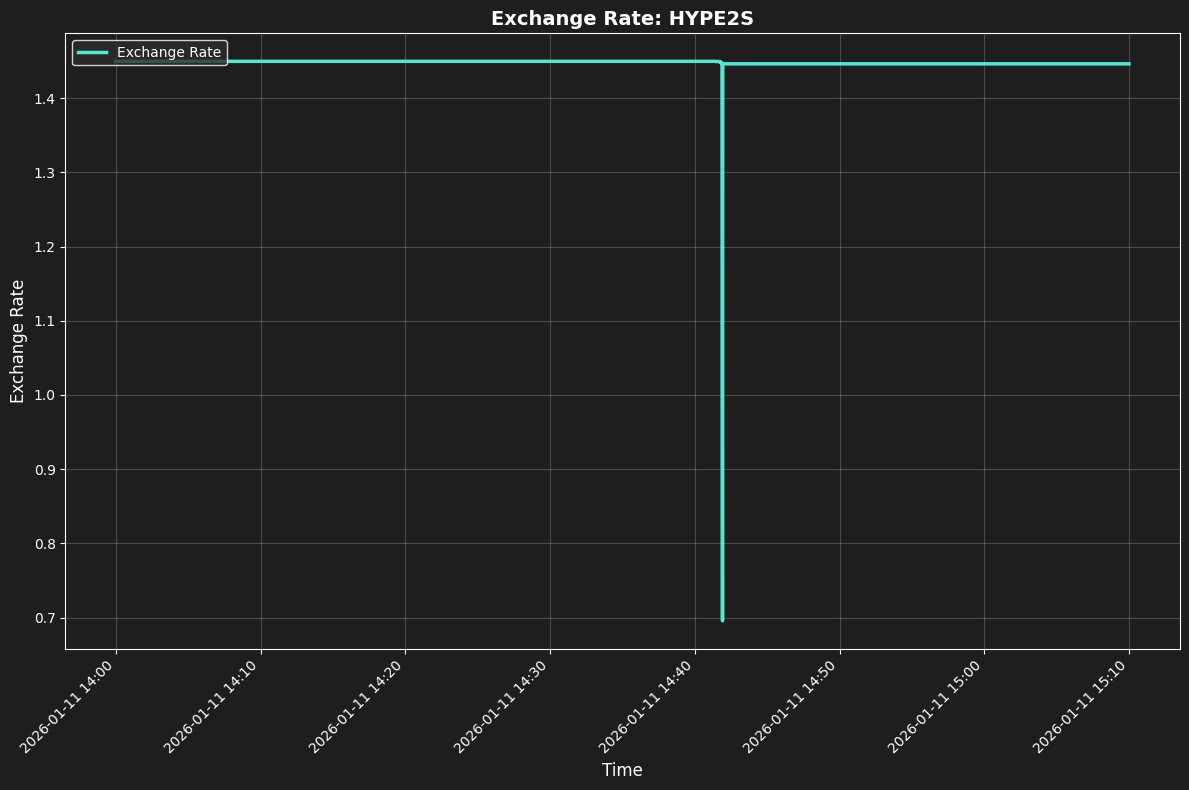
Sharp and unexpected changes in values that last only for a single block. A scary thought, as with many views this could lead to an exploit. So what is going on here?
As a specific example for this issue, let us refer back to our bridging contract, and our totalAssets view. For the bridgeFromPerp function. Here is a diagram for the flow of funds:
We make the CoreWriter Action call in EVM block n. Nothing happens in that block though, as the action is fully async here so will be processed in part between blocks, and in part at the start of the next block. Between blocks the Perp balance is decreased, so from block n plus 1 onwards, the perp balance is 0 as expected. The way that the USDC bridge works is that it is done as a transfer to the destination, but at the very start of the block. That means, that at the start of the block, before the transfer happens, the funds have magically disappeared again. However, because the transfer always happens at the start of the block, we know that any transactions we have in that block will be after the transfer, and so the funds will appear in our EVM balance. So practically, on the EVM side, we have a full track of funds at all times and there is no issue.
However, for an RPC provider, it is not practical for them to return view data from the perspective of what an expected EVM transaction would experience part way through a block. And so, depending on how the RPC is implemented, they return 0 for both the spot and perp balance, usually in block n plus 1 and sometimes in block n. We replicated this behaviour with every RPC we tested, and our auditors tested with.
So we have a weird form of Schrodinger's box, where the cat is either dead or alive, depending on who is opening the box.

There is no clean solution for this problem that we have found. The options at a high level are to resolve this offchain, by looking at event logs to detect when a bridge happened, and then modify the response for the following block based on that. Or to resolve this onchain, by writing to storage when a bridge happens, and return some modified view that is only read by RPCs that increments this amount for that block. Or, to just avoid reading from RPC views in the blocks following a bridge. In other words, to just avoid opening the box.
API Wallets
In an ideal world, the CoreWriter Actions should contain everything you need to build your protocol. That way you can keep all logic fully self contained within the smart contract. We are so close to this, however some obvious and critical things are missing. As an example, if you are wanting to build some vault that is backed by a perp position. You need a few CoreWriter Actions to achieve this:
- Bridge between HyperEVM and HyperCore Spot
- Convert between HyperCore Spot to HyperCore Perp
- Update Leverage
- Create an Order on HyperCore
Inconveniently, we have everything we need from this list, but missing the simplest of all of these, which is the ability to Update Leverage using a CoreWriter Action.
This means that to achieve this goal, API Wallets are needed. API Wallets allow an external wallet to make actions on behalf of a user. The user adds a wallet as an API Wallet for itself, and can also remove this permission later. An API Wallet needs to not have any previous history on HyperCore to be added as an API Wallet. There is a CoreWriter Action to add an API Wallet, so this can be achieved with smart contracts. Essentially, the helm of the boat is passed over to an API Wallet friend to control things for a bit.
However, as usual, there is another inconvenience here. For some reason, API Wallets are not able to convert between HyperCore Spot and Perp balances for a user. So instead the final architecture needs to be a hybrid, where the API Wallet makes some calls and the smart contract makes some calls. Just to achieve what would be described as one of the most primitive and marketed use cases of Precompiles. To bring HyperCore liquidity onto HyperEVM.
Tooling
So, we have weathered the storm, and docked at port. We have got a working smart contract, with all edge cases handled, and the anchor is out. What is the experience outside of the code for developing and maintaining a protocol on HyperEVM?
Inconveniently there are some challenges developing on HyperEVM with Foundry. One is that there is no test tooling that allows for the real simulation of calls to any Precompile or CoreWriter Actions. So the only way to test this for real is to deploy to production. In a codebase you will find endless mocks are needed to test the flow of funds. Also, using Foundry scripts, you are not able to make any calls that read from a Hyperliquid Precompile. So if a smart contract contains a precompile read as part of deployment, then the protocol instead has to be deployed in JavaScript or Python. If any maintenance functions require a Precompile read, then again you are out of Foundry.
The developer support is tough. The docs are missing lots of data, and there is little community support when you get stuck. Helpful support from community members can make a big difference when questions come up, but for the wider public that is building and just using public support channels and docs, there is regular feedback about the inability to find information. To anonymously quote one of our auditors, "The docs were even contradicting some time, and got little, sometimes even hostile, responses in Discord".

There are still a lot of major infra providers that are not on HyperEVM yet. A common model these infra providers use is that the blockchain pays them to set up their infrastructure on that chain, and then the infra is free for all users on that chain. However, Hyperliquid has a strict policy that they do not pay for integrations. Which means that for the foreseeable future, any infra provider with this pricing model will not be on HyperEVM.
It was still possible to find enough great infra providers to build out Bounce Tech. A few that worked well were:
- Alchemy and QuickNode for a HyperEVM enabled RPC
- Ponder as an indexing solution
- HypeRPC as a drop in replacement for the Hyperliquid API with higher rate limits
- LiFi for an npm package for adding bridging support
- hyper-evm-lib as a must have library for any Precompile integration
While not a tool specifically, auditors with experience in the Hyperliquid Precompiles can help a lot. Examples include Guardian Audits, Obsidian and Phage. We have also heard good things about Bailsec but have not had a chance to work with them yet.
How do we improve?
How can we strengthen the Hyperliquid ship, and stop the leak? The biggest single win for the development experience on HyperEVM would be the introduction of a Developer Relations team. Despite all of the challenges of integrating, having a point of call to help out during these times would have saved months of work. Someone to jump on a call with and walk through some of the current blockers. This would enable teams to deliver products much faster, and much more securely to HyperEVM and would be a massive unlock for the space.
And from this, to have a meaningful product feedback loop. If there are regular complaints that some aspect of the integration is not clear. Then the docs should be updated to help with this. Developers should be reached out to see what features they would like and what could be improved, and that feedback should be fed back into the development lifecycle. It feels like right now there is not currently a positive feedback loop. The same questions are asked again and again in Discord, usually unanswered. And not unfounded, as there is simply no information online about them.
In terms of what actual features or changes would help. A big one is HIP 3 precompile support, it would be great to have the ability to bring these onto HyperEVM. A centralised fee and gas bank would be a big UX improvement, add HYPE to some core balance, and all of your bridging and API Wallet calls would be covered by that for delegated contracts and agents. Historic Precompile reads would be a massive improvement if somehow possible. Adding an Update Leverage CoreWriter Action would add the missing piece for fully onchain trading. And allowing USD Class Transfer calls from an API Wallet would also improve API Wallet flows quite a lot.
It is worth noting that while the development experience currently is not great. It is still very early. A lot of this tech is still very new. There are a huge amount of incredible developers and community members that are working to improve the space every day. We remain highly optimistic about the future of Hyperliquid and the HyperEVM. But optimism only matters if we're willing to fix what's broken.